迷失在冗长的思考链:大模型如何学会“见好就收”
人工智能领域曾流传着一个令人哭笑不得的场景。当用户向大模型询问一个极为基础的问题,例如单词HiPPO中包含多少个字母P时,模型却仿佛陷入了沉思,不仅开始长篇大论地解析河马的生物学定义,还详细拆解了字母的排列组合逻辑。这种现象在技术界被称为过度思考,它不仅消耗了宝贵的计算资源,还显著增加了用户的等待时间。
早期的模型训练路径往往倾向于鼓励链式思考,这种模式在解决复杂数学或编程难题时确实表现卓越,但当面对简单任务时,这种思维惯性便成了负累。研究数据显示,这种非必要的深度推理直接导致了Token使用量的激增和推理延迟的上升,在追求交互体验的实际应用场景中,这成为了一个亟待解决的瓶颈。
智能决策的范式转移
面对这一行业痛点,快手KwaiKAT团队与南京大学科研团队联合推出的HiPO框架提供了一种全新的破局思路。该框架不再强制模型进行单调的思考,而是赋予了模型自主判断的权利,使其能够根据任务复杂度动态决策何时该深思熟虑,何时该直接给出结果。
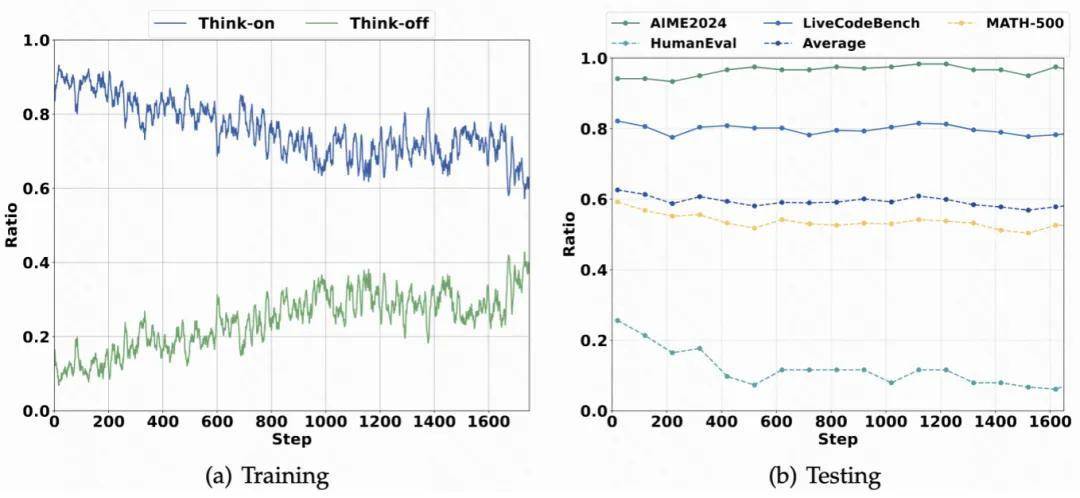
通过引入混合数据冷启动机制,HiPO框架在模型训练初期就构建了包含推理与直接回答两种模式的高质量语料库。模型不再是机械地执行指令,而是通过学习不同任务的特征,将模式选择与问题内在逻辑进行深度对齐,从而实现了从无脑思考到智能决策的跨越。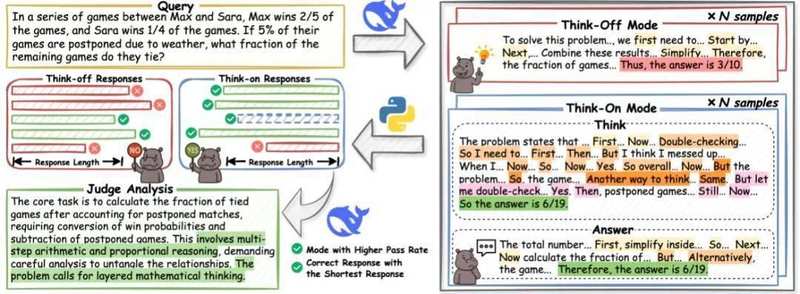
数据驱动下的性能飞跃
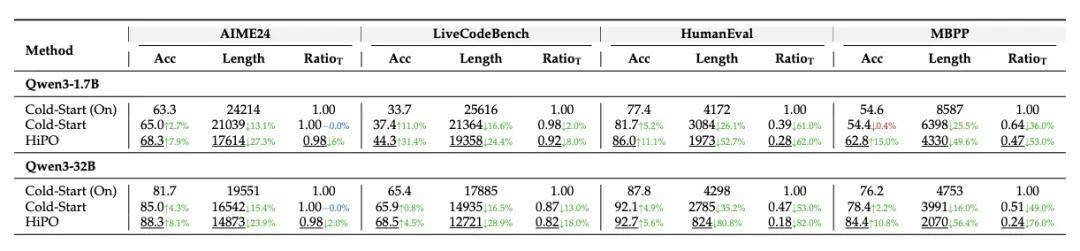
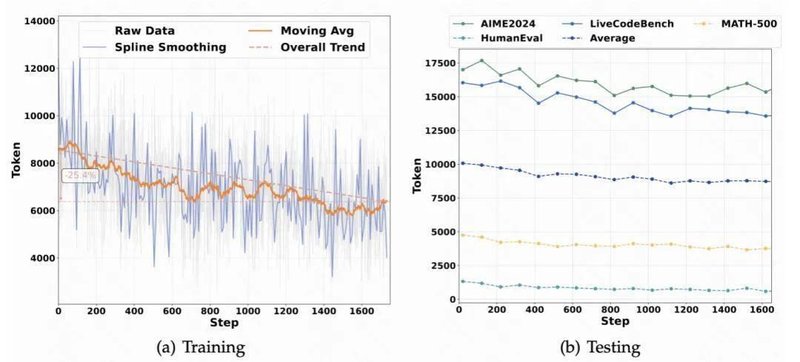
在实际测试中,HiPO展现出了惊人的效能提升。实验结果表明,该模型在保持甚至提升准确率的前提下,平均令牌长度减少了30%,思考率降低了37%。这意味着在处理大量日常任务时,系统响应速度得到了质的飞跃,同时运行成本得到了有效控制。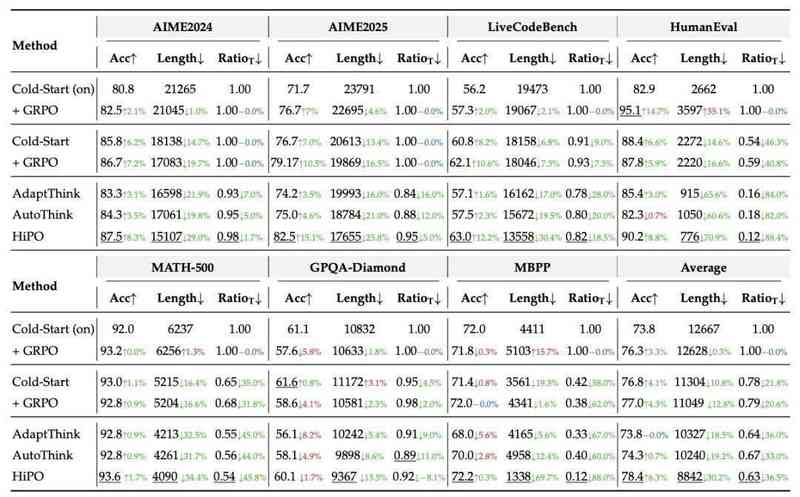
更深层次的分析显示,模型在AIME、LiveCodeBench等高难度任务中,依然保持了超过70%的深度思考激活率,这证明了HiPO在追求效率的同时,并未牺牲模型处理复杂问题的核心能力。这种在质与效之间的精细平衡,为构建下一代高效人工智能助手开辟了广阔路径。